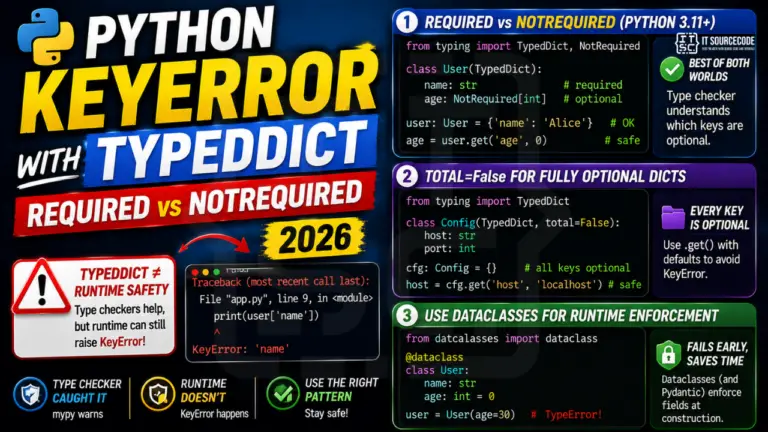
SQLAlchemy KeyError on Row Access: 3 Fixes (2026)

A Python KeyError on SQLAlchemy row access usually means you tried row[‘column_name’] on a Row object that uses positional access in 2.0+. The fix in modern SQLAlchemy is row._mapping[‘column_name’] or …