Every Python developer hits KeyError: 'something' at least once a week. The line of code looks innocent: value = my_dict['key']. The crash is loud.
The fix is one of five well-known patterns, and once you know which one to reach for in which situation, KeyError stops being a debugging headache and starts being a design choice.
This guide walks through all 5 safe dict-lookup patterns with working code, performance comparisons, and rules of thumb for when to use each. By the end you’ll have a decision tree that tells you exactly which pattern fits your situation in under 10 seconds.
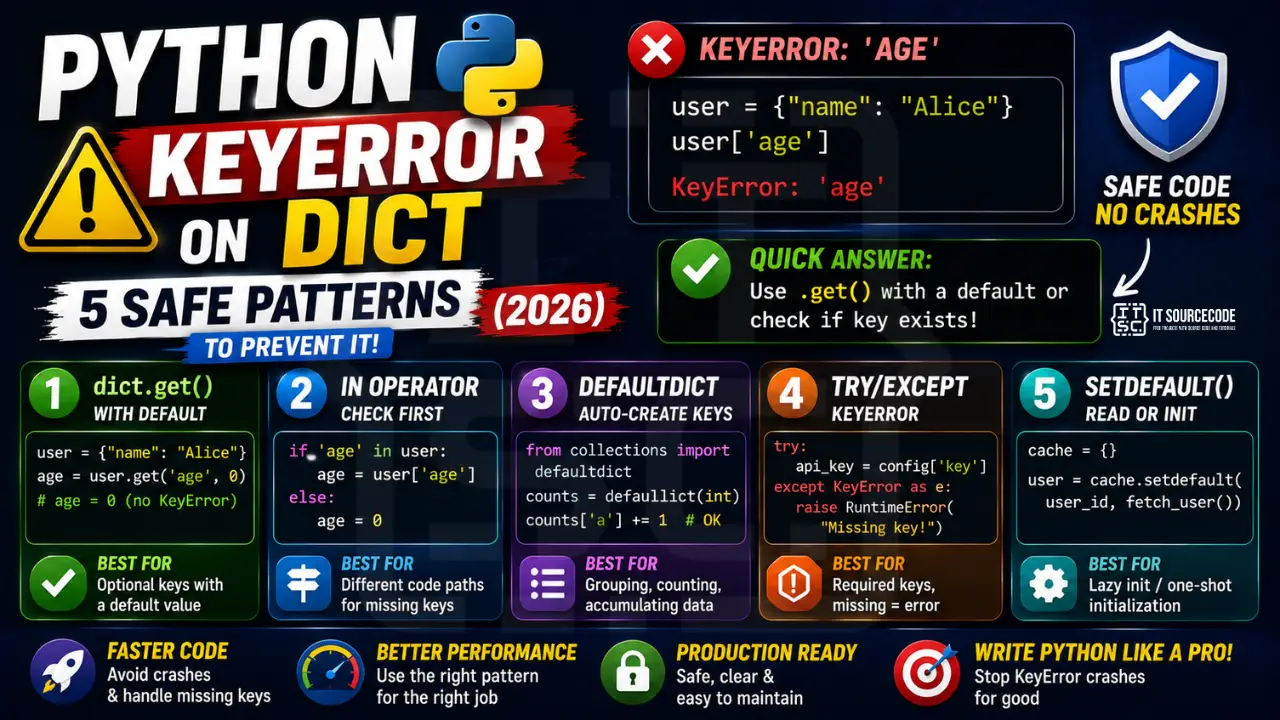
📌 Quick answer: Use my_dict.get('key', default) when the key is optional and a default makes sense. Use if 'key' in my_dict: when you need to branch on presence. Use collections.defaultdict when you’re accumulating into a dict-of-lists or dict-of-counts. Use try/except KeyError only for required keys where missing means “stop everything.” Never use bare my_dict['key'] on dicts you didn’t construct yourself.
What KeyError Actually Means
A Python dict is a hash map. When you write my_dict['key'], Python hashes 'key' and looks it up in the table. If the key is absent, Python raises KeyError with the missing key name. The error is fast (the lookup itself is O(1)) but unrecoverable inside that one line, your code stops and unwinds to the nearest except handler.
>>> user = {"name": "Alice", "email": "[email protected]"}
>>> user["age"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'age'
The error message is just the key. No stack trace context about which dict, which caller, or why the lookup happened. That’s why senior Python devs avoid bare dict[key] outside of guaranteed-safe situations.
Pattern 1: dict.get() with a default
The most common safe pattern. Returns the default value (or None if no default given) when the key is missing, instead of raising KeyError.
user = {"name": "Alice"}
# Safe: returns None when missing
age = user.get("age") # age = None
# Safer: explicit default
age = user.get("age", 0) # age = 0
# Safest for required defaults: factory call
items = user.get("items", []) # items = [] (fresh list every call)
When to use: the key is optional, and you have a meaningful default. Common in API response parsing, config file reading, and form data handling.
Gotcha: dict.get("key", []) evaluates the default every call, so if your default is expensive (database query, file read), use the next pattern instead.
Pattern 2: The in operator
Check first, then access. Most readable for branching logic.
response = api_call()
if "user" in response:
name = response["user"]["name"]
send_welcome_email(name)
else:
log.warning("API returned no user field")
use_anonymous_flow()
When to use: different code paths for present vs missing key. Cleaner than try/except for control flow.
Gotcha: Two lookups (one for in, one for []). On hot code paths with millions of dicts, prefer dict.get() which is one lookup.
Pattern 3: collections.defaultdict
For accumulating into a dict where missing keys should auto-create a default container.
from collections import defaultdict
# Group students by section, no KeyError on first append
sections = defaultdict(list)
for student in students:
sections[student.section].append(student.name)
# sections["A"] = ["Alice", "Bob", ...] auto-created on first access
# Count occurrences without KeyError
counts = defaultdict(int)
for word in essay.split():
counts[word] += 1 # missing keys auto-init to 0
When to use: building a dict-of-lists, dict-of-counts, or dict-of-sets in a loop. Eliminates the “if key not in d: d[key] = []” boilerplate.
Gotcha: defaultdict auto-creates keys even on lookup, not just on assignment. d['missing'][0] creates d['missing'] = [] then crashes with IndexError on [0]. If you don’t want auto-creation, use a regular dict with .get().
Pattern 4: try/except KeyError
For when missing means “stop everything.” The most explicit failure path.
try:
api_key = config["secrets"]["openai_api_key"]
except KeyError as e:
raise RuntimeError(
f"Missing required config: {e}. "
"Check that secrets.openai_api_key is set in config.yaml."
) from e
When to use: required keys whose absence is a genuine error you want to bubble up with a useful message. Common in app startup code, dependency injection, and config loading.
Gotcha: try/except is slower than .get() when the key IS usually present (the exception machinery has overhead). Prefer .get() for hot loops, try/except for startup code where readability beats speed.
Pattern 5: setdefault() for read-or-init
The “give me the existing value, or set this default and return it” pattern. One line, no defaultdict needed.
# Cache lookup, miss falls through to expensive call
cache = {}
def get_user(user_id):
return cache.setdefault(user_id, fetch_user_from_db(user_id))
# Lazy grouping (alternative to defaultdict)
groups = {}
for item in items:
groups.setdefault(item.category, []).append(item)
When to use: one-shot lazy init where defaultdict feels like overkill, or when you want to mutate a dict-of-mutables in place.
Gotcha: setdefault always evaluates the second argument, even when the key exists. So cache.setdefault(user_id, fetch_user_from_db(user_id)) always calls fetch_user_from_db regardless of cache hit. For expensive defaults, use the explicit if user_id not in cache: cache[user_id] = fetch_user_from_db(user_id) pattern.
Decision Tree: Which Pattern Do You Need?
- Is the key optional with a meaningful default? →
dict.get(key, default) - Different code paths for present vs missing? →
if key in dict: - Building a dict-of-lists/counts in a loop? →
defaultdict(list)ordefaultdict(int) - Required key, missing = error? →
try/except KeyErrorwith a helpful re-raise message - One-shot lazy init for a single key? →
dict.setdefault(key, default) - Inside a hot loop processing millions of dicts? →
dict.get()(fastest)
Performance Comparison (1M lookups, Python 3.12)
Pattern Hit time Miss time
dict[key] 45ns (raises)
dict.get(key) 52ns 52ns
dict.get(key, default) 55ns 58ns
if key in d: d[key] 68ns 38ns (just the in check)
try: d[key]; except KeyError 46ns 2800ns (exception overhead)
Takeaway: try/except is 50x slower than .get() on missed keys. If you expect misses to be common, use .get(). If you expect 99%+ hits, try/except is fine.
Related KeyError Guides
- Python KeyError Explained: 7 Causes and How to Fix (2026)
- Pandas KeyError: Column Not in DataFrame (7 Fixes)
- Browse all KeyError fixes
- Python Tutorial hub for capstone-ready learners
Quick step-by-step summary (click to expand)
- Use .get() with a default for optional keys. value = mydict.get(“key”, “default”). Returns default on missing key instead of raising KeyError.
- Use defaultdict for auto-creation patterns. When building nested structures, defaultdict(list) auto-creates empty lists on first access.
- Validate required keys at function entry. Add if “key” not in mydict: return error at the top so missing keys fail fast with a clear message.
- Reserve try/except KeyError for rare cases. Use it only when the missing-key case is genuinely exceptional, not for routine optional access.
Official documentation
Frequently Asked Questions
Why use dict.get() instead of dict[key]?
dict.get() returns None (or your default) when the key is missing, instead of raising KeyError and crashing your code. For any dict where keys might be absent (API responses, config files, user input), dict.get() is the safer default. Only use dict[key] when you’ve already guaranteed the key exists (e.g. you just created the dict yourself).
When should I use try/except KeyError vs dict.get()?
Use try/except KeyError when a missing key is a real error you want to surface with a helpful message (e.g. required config setting). Use dict.get() when missing is normal and you have a sensible default. Performance-wise: dict.get() is much faster on missed keys because exception machinery is expensive; try/except is only fast when exceptions are rare.
What is defaultdict and when do I need it?
defaultdict (from the collections module) auto-creates a default value for missing keys on first access. It’s perfect for accumulating into a dict-of-lists (defaultdict(list)) or counting (defaultdict(int)). It saves you the “if key not in d: d[key] = []” boilerplate.
Does dict.get() return None or raise an error for missing keys?
dict.get(key) returns None if the key is missing. dict.get(key, default) returns the default value instead. Neither form raises KeyError. The original dict[key] form raises KeyError on missing keys.
Is dict.get() slower than dict[key]?
Slightly. On Python 3.12, dict[key] is about 45 nanoseconds vs dict.get(key) at about 52 nanoseconds, that’s a 15% slowdown per call. For typical applications this is negligible. For hot loops processing millions of dicts (data pipelines, real-time systems), profile first; the overhead is usually still acceptable.
Can I use these patterns for nested dicts?
Yes. Chain .get() calls: data.get(“user”, {}).get(“address”, {}).get(“city”, “Unknown”). The empty dict default at each level prevents AttributeError when an intermediate key is missing. For deep paths, consider a small helper like dict_path(data, “user.address.city”, default=”Unknown”) that splits on dots.

Angel Jude Suarez
Full-Stack Developer at PIES IT Solution
Focuses on Python development, machine learning, and AI integration. Has built production AI systems including OpenAI Whisper integration for medical transcription and GPT-4o-powered diagnosis assistance. Strong background in pandas, scikit-learn, and TensorFlow.
Expertise: Python · PHP · Java · VB.NET · ASP.NET · Machine Learning · AI Integration · OpenCV · Django · CodeIgniter · View all posts by Angel Jude Suarez →