Real-Time Object Detection using OpenCV Python With Source Code
The Real-Time Object Detection OpenCV Python was developed using Python OpenCV, this openCV real-time object detection script is a simple experimental tool to detect common objects (COCO) easily with your built-in webcam.
It uses OpenCV’s readNet method and uses the external yolov3-tiny model (which can be upgraded to the full-sized model).
Opencv’s readNet method only runs on CPU (and not GPU), is very intensive, and therefore, it will not be optimal for big AI projects.
An Object Detection OpenCV Python implements an image and video object detection classifier using pretrained yolov3 models.
The yolov3 models are taken from the official yolov3 paper which was released in 2018. The yolov3 implementation is from the darknet.
Also, this project implements an option to perform classification in real time using the webcam.
Project Information’s
| Project Name: | Real-Time Object Detection OpenCV Python With Source Code |
| Language/s Used: | Python (OpenCV) |
| Python version (Recommended): | 2.x or 3.x |
| Database: | None |
| Type: | Deep Learning Project |
| Developer: | IT SOURCECODE |
| Updates: | 0 |
About The Project
In this Python OpenCV Project, we also include a downloadable Python Project With Source Code for free, just find the downloadable source code below and click to start downloading.
By the way, if you are new to Python programming and don’t know what Python IDE to use, I have here a list of the Best Python IDE for Windows, Linux, and Mac OS that will suit you.
I also have here How to Download and Install the Latest Version of Python on Windows.
To start executing this project, make sure that you have installed Python 3.9 and PyCharm on your computer.
How to run the Real-Time Object Detection using OpenCV Python: A step-by-step Guide with Source Code
Time needed: 5 minutes
These are the steps on how to run Real-Time Object Detection OpenCV Python With Source Code
- Step 1: Download the given source code below.
First, download the given source code below and unzip the source code.

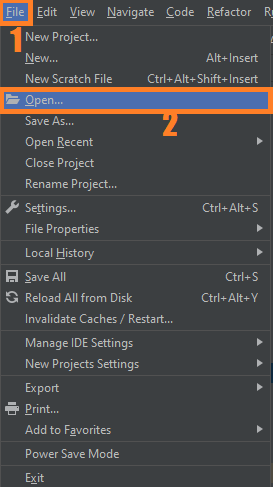
- Step 2: Import the project to your PyCharm IDE.
Next, import the source code that you’ve downloaded to your PyCharm IDE.

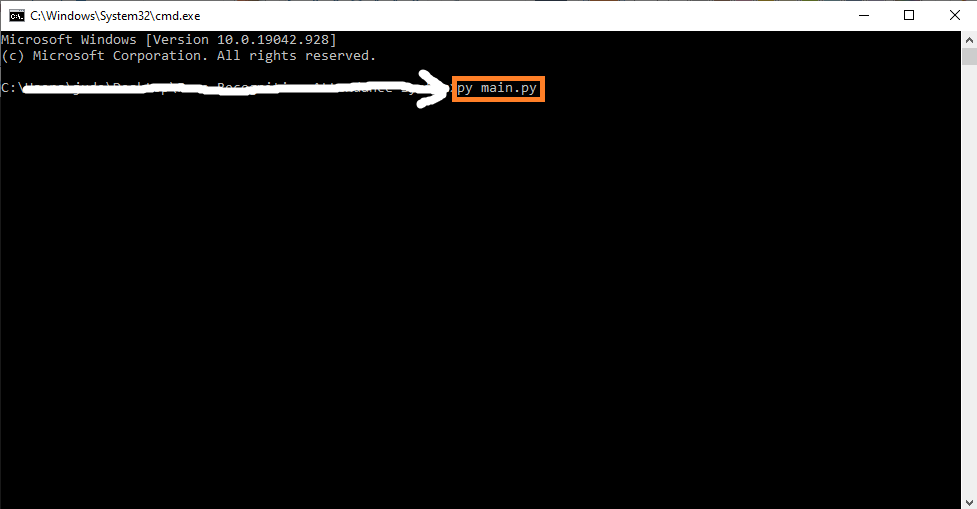
- Step 3: Run the project.
Lastly, run the project with the command “py main.py”

Installed Libraries
import cv2 import numpy as np import time
Complete Source Code
import cv2
import numpy as np
import time
# Load the YOLO model
net = cv2.dnn.readNet("./weights/yolov3-tiny.weights", "./configuration/yolov3-tiny.cfg")
classes = []
with open("./configuration/coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(0, 255, size=(len(classes), 3))
# Load webcam
cap = cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
starting_time = time.time()
frame_id = 0
while True:
# Read webcam
_, frame = cap.read()
frame_id += 1
height, width, channels = frame.shape
# Detecting objects
blob = cv2.dnn.blobFromImage(frame, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# Visualising data
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.1:
# Object detected
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# Rectangle coordinates
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.8, 0.3)
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
confidence = confidences[i]
color = colors[class_ids[i]]
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
cv2.putText(frame, label + " " + str(round(confidence, 2)), (x, y + 30), font, 3, color, 3)
elapsed_time = time.time() - starting_time
fps = frame_id / elapsed_time
cv2.putText(frame, "FPS: " + str(round(fps, 2)), (40, 670), font, .7, (0, 255, 255), 1)
cv2.putText(frame, "press [esc] to exit", (40, 690), font, .45, (0, 255, 255), 1)
cv2.imshow("Image", frame)
key = cv2.waitKey(1)
if key == 27:
print("[button pressed] ///// [esc].")
print("[feedback] ///// Videocapturing succesfully stopped")
break
cap.release()
cv2.destroyAllWindows()Output:

Download the Source Code below
Summary
This project implements an image and video object detection classifier using pretrained yolov3 models.
The yolov3 models are taken from the official yolov3 paper which was released in 2018.
The yolov3 implementation is from the darknet.
Also, this project implements an option to perform classification in real-time using the webcam.
Related Articles
- Code For Game in Python: Python Game Projects With Source Code
- Best Python Projects With Source Code FREE DOWNLOAD
- How to Make a Point of Sale In Python With Source Code
- Python Code For Food Ordering System | FREE DOWNLOAD
- Inventory Management System Project in Python With Source Code
Inquiries
If you have any questions or suggestions about Real-Time Object Detection OpenCV Python With Source Code, please feel free to leave a comment below.
Official documentation
Frequently Asked Questions
How does real-time object detection work in OpenCV?
Uses a pretrained deep-learning model loaded via OpenCV’s DNN module. Popular options: MobileNet-SSD (lightweight, runs on CPU), YOLO v3/v4/v5/v8 (faster and more accurate, slight GPU benefit), Faster R-CNN (highest accuracy, GPU recommended). Each model returns bounding boxes, class labels, and confidence scores for 80 COCO classes (person, car, dog, chair, etc.) at 20-60 FPS on CPU.
What Python and library versions do I need?
Python 3.10, 3.11, or 3.12 (avoid 3.13 until all DL wheels catch up). Install with: pip install opencv-python numpy. For deep learning models add: tensorflow keras (CPU build is fine for most demos), torch torchvision (PyTorch alternative), mediapipe (for face/hand/pose). Some projects also need: pytesseract for OCR, pyzbar for barcode, dlib for legacy face-landmark predictor.
Do I need a GPU to run this deep learning project?
For inference on a pretrained model: no, CPU runs at 10-30 FPS for most computer-vision tasks. For TRAINING a custom model: GPU strongly recommended (CPU works but slow). Free GPU options for training: Google Colab Free (12-hour sessions, sufficient for most BSIT capstones), Kaggle Notebooks Free. Buying a $1000+ GPU just for capstone is overkill.
Can I use this deep learning project for a BSIT or CSE capstone?
Yes, but extend it. A single OpenCV deep-learning demo (face detection, object detection alone) is too narrow for full capstone scope. Combine with a real domain wrapper: an attendance system using face recognition, a traffic monitoring system using vehicle detection, a wildlife camera using object detection, a driver-monitoring app using drowsiness detection. Add database logging, simple UI, and Chapter 1-5 manuscript.
Why does my model give wrong predictions or low accuracy?
Three most common causes: (1) Input preprocessing mismatch: the model expects 224×224 RGB normalized to [0,1] or [-1,1]; using BGR (OpenCV default) or wrong size produces garbage. (2) Insufficient training data: if you trained your own model on under 1,000 samples per class, accuracy plateaus low. Augment with cv2.flip, rotate, brightness shifts. (3) Lighting and angle drift between training and live use: train on data that matches the deployment environment.
Where can I find more deep learning project ideas with source code?
Browse our Deep Learning Projects hub for 19+ vision demos. For broader AI / ML / RAG / NLP capstones see 100+ AI Capstone Project Ideas. For pure ML (no deep learning) see Machine Learning Projects.

Angel Jude Suarez
Full-Stack Developer at PIES IT Solution
Focuses on Python development, machine learning, and AI integration. Has built production AI systems including OpenAI Whisper integration for medical transcription and GPT-4o-powered diagnosis assistance. Strong background in pandas, scikit-learn, and TensorFlow.
Expertise: Python · PHP · Java · VB.NET · ASP.NET · Machine Learning · AI Integration · OpenCV · Django · CodeIgniter · View all posts by Angel Jude Suarez →
May I please ask if it is possible to use one data base which has certain information about object , the real time scanning to scan object and use certain certain mark or shape from real time video / scanning to identify that object . Also possible to use multiple database just to make sure AI software pick up 100% right identification of object ?
You will use one database only because if it is multiple the system will be redundant